Data Science and Neuroinformatics
Ariel Rokem, University of Washington eScience Institute
Slides available at:





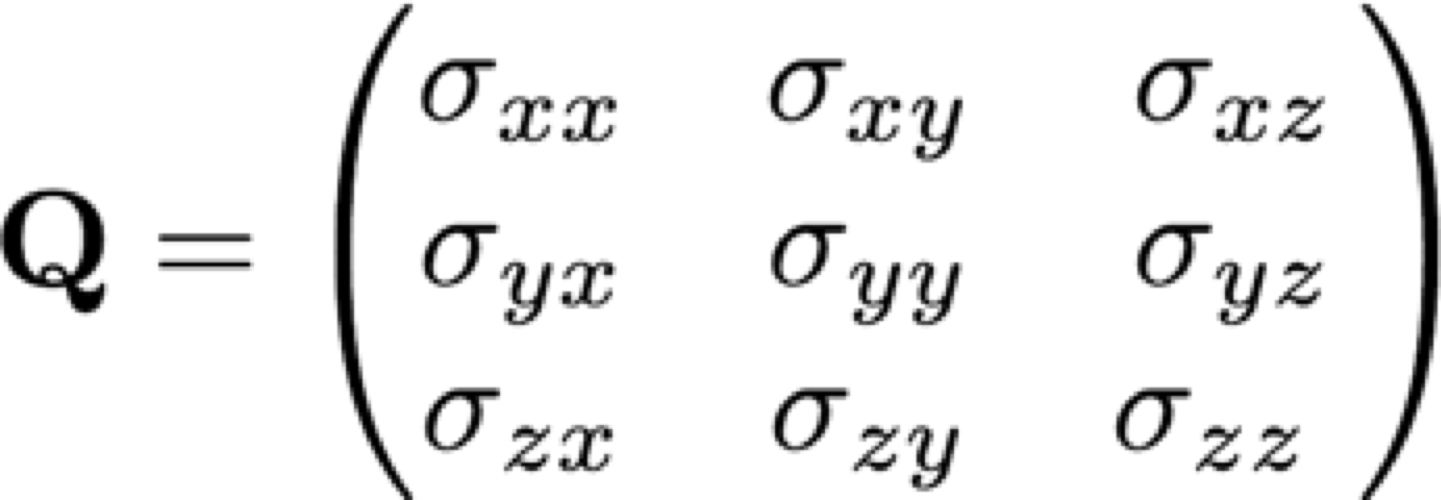
The era of brain observatories
Allen Institute for Brain Science
n=1200
n=~10,000
n=~10,000
n=500,000
Opportunities
New data sets will enable important new discoveries
Data-driven discovery
Challenges
Data arriving at unprecedented volume, variety and velocity
=> Instead of moving the data to the compute, need to bring the compute to the data
=> Need new tools and approaches to process, analyze and interpret
=> Web-based analysis tools become first-class citizens in our tool-kit
=> New sociotechnical structures needed to facilitate training and collaboration
Bringing the compute to the data
To the cloud!
Infinitely scalable
"Elastic"
But the cloud is hard to operate
Challenge: accessible cloud computing

Adam Richie-Halford
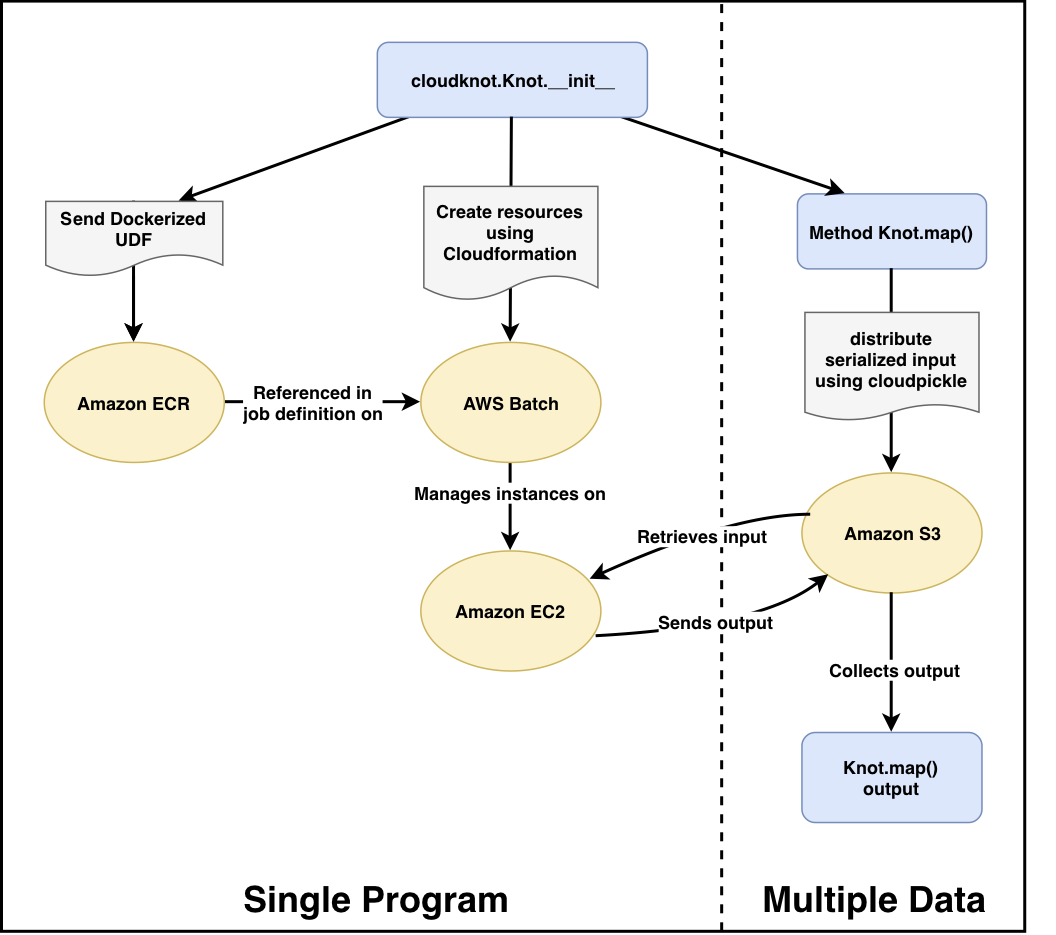
Cloudknot: package your code and run it on AWS Batch
import cloudknot as ck
def awesome_func(...):
...
knot = ck.Knot(func=awesome_func)
...
future = knot.map(args)
Scaling expertise with citizen science

Anisha Keshavan

Jason Yeatman
https://braindr.us
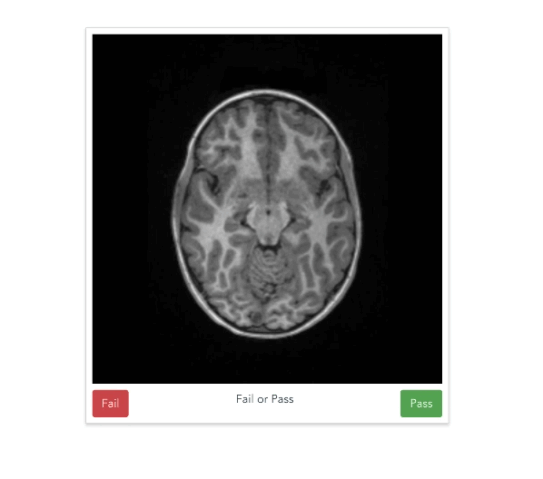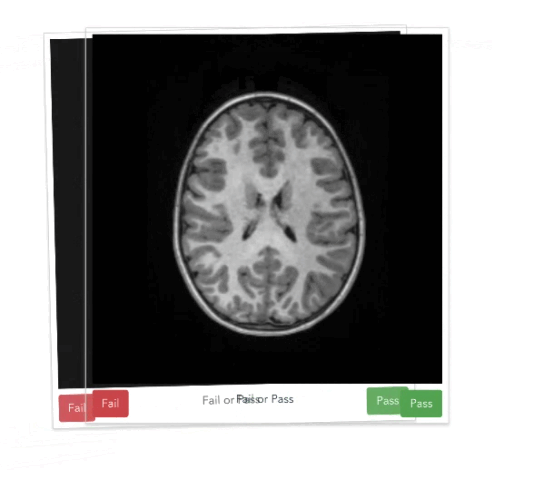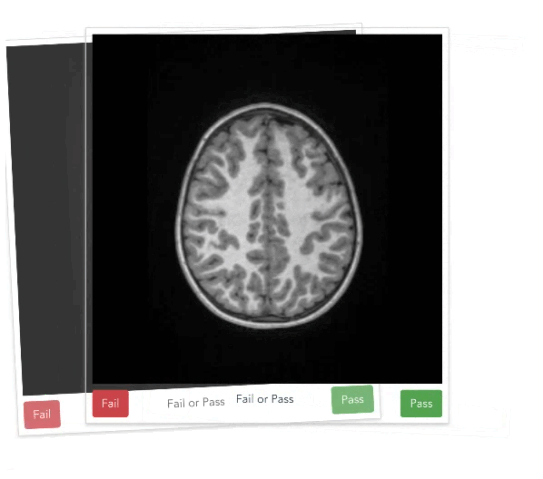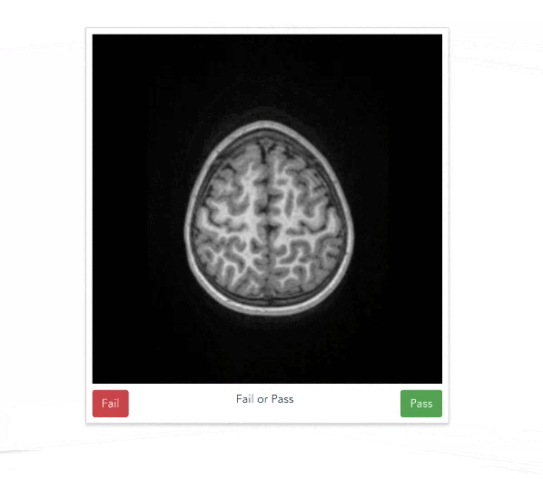
Multiple ratings per image
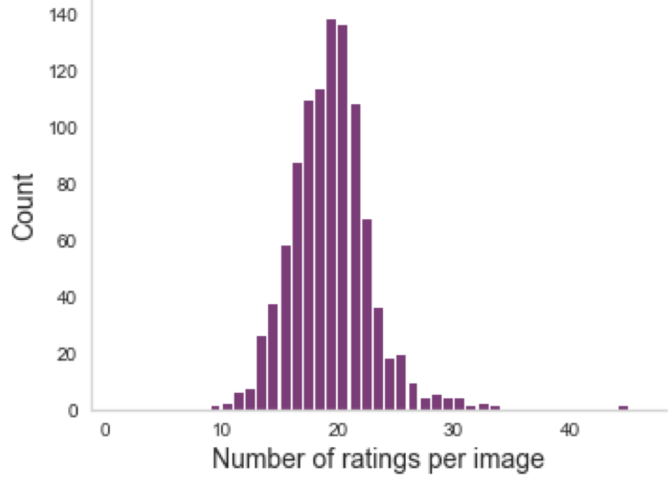
Aggregating across raters
XGBoost (Chen & Guestrin, 2016)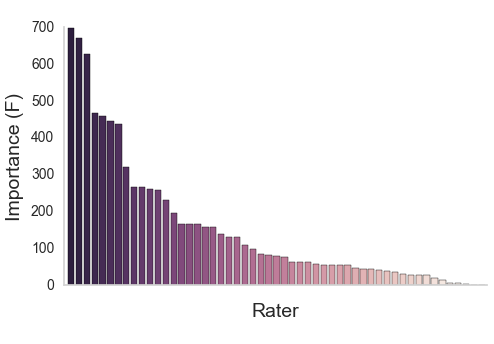
Scaling expertise using citizen scientist ratings
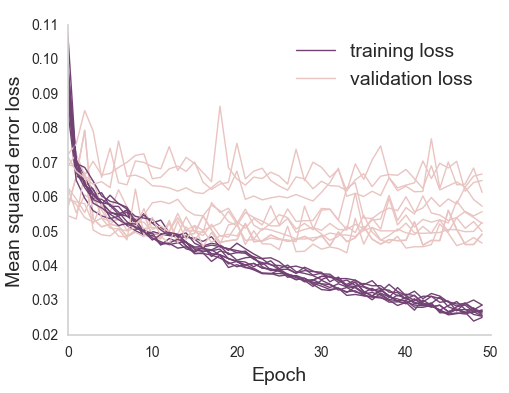
Scaling expertise using citizen scientist ratings
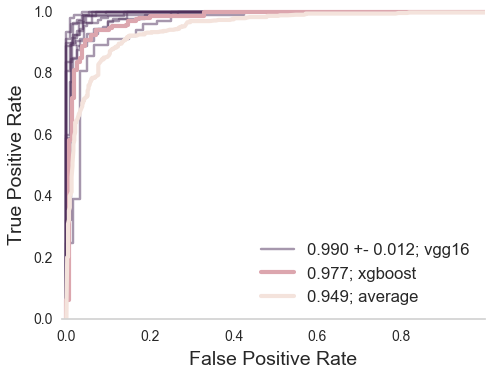
Challenge: tools for exploration of complex data
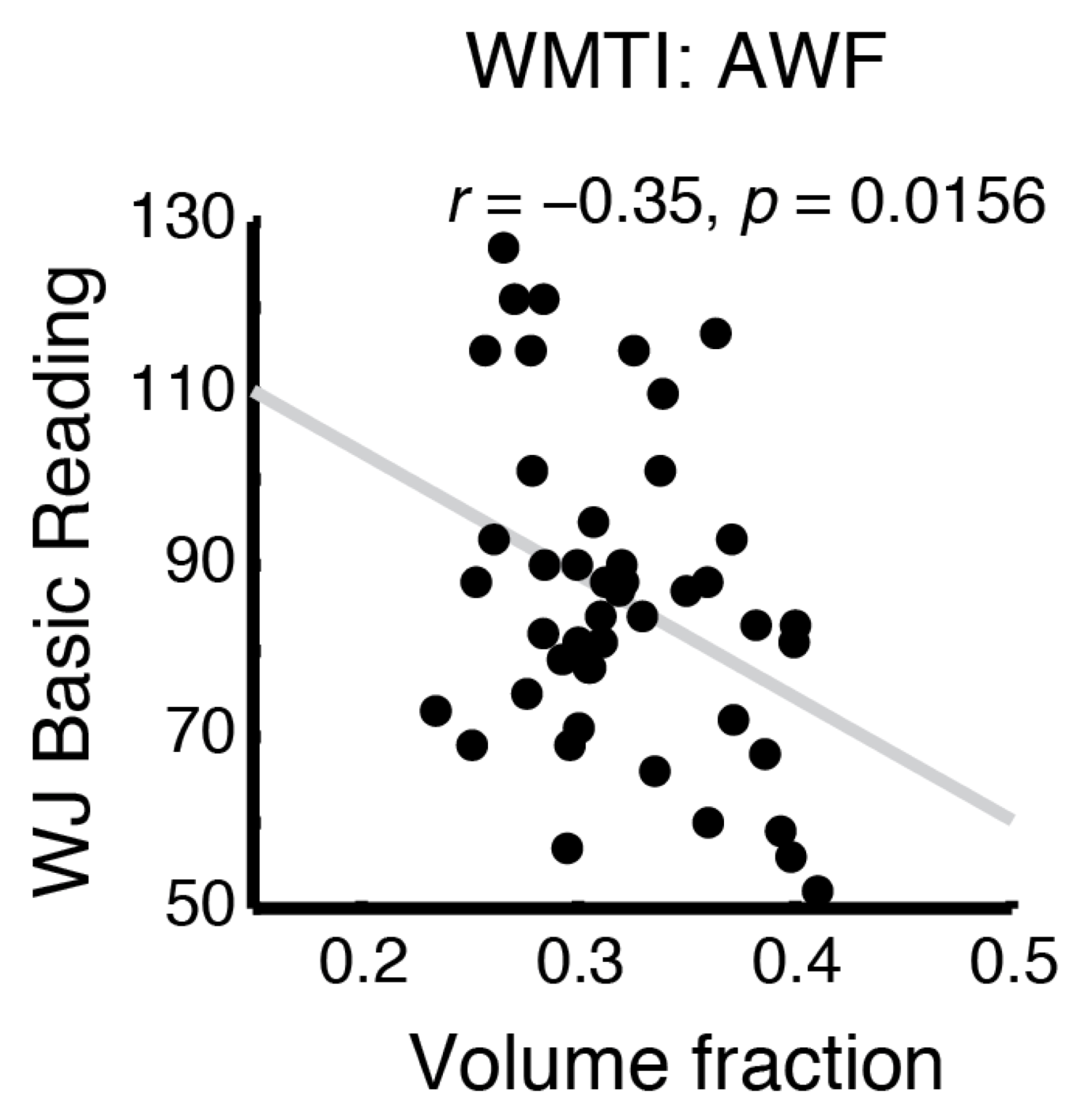
Results from large datasets are hard to understand
Hard to communicate
Hard to reproduce
Data sharing is not incentivized and is not easy enough
Sharing and exploring large datasets on the web
Jason Yeatman
Adam
Richie-Halford

Josh Smith
Anisha
Keshavan
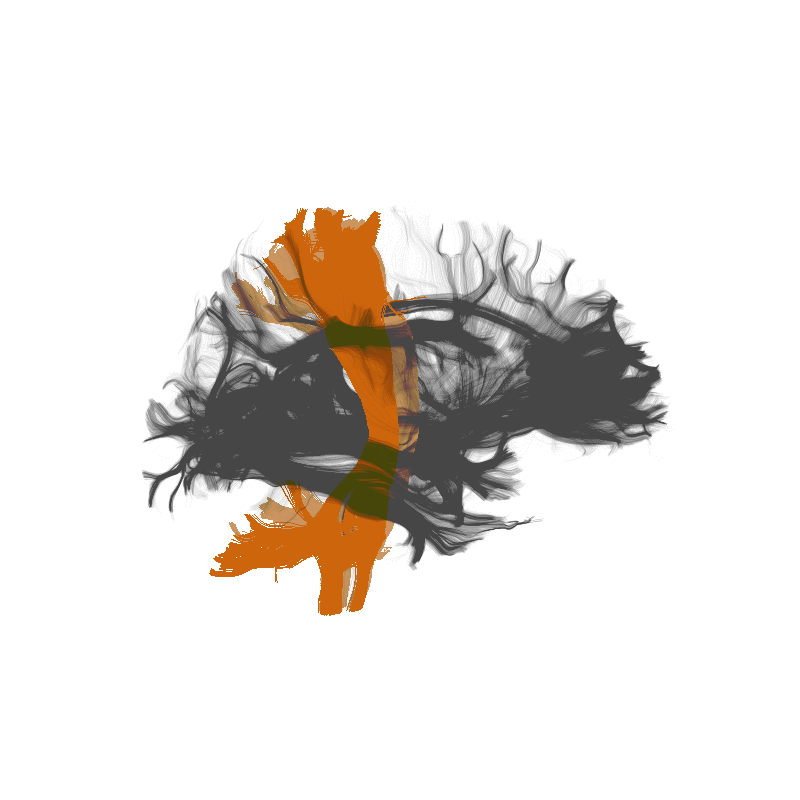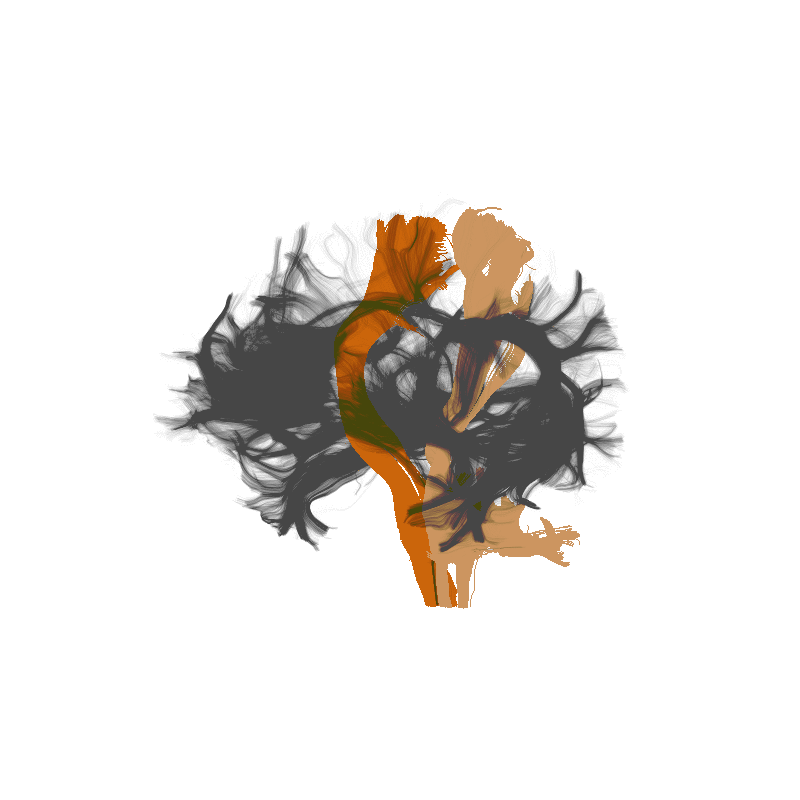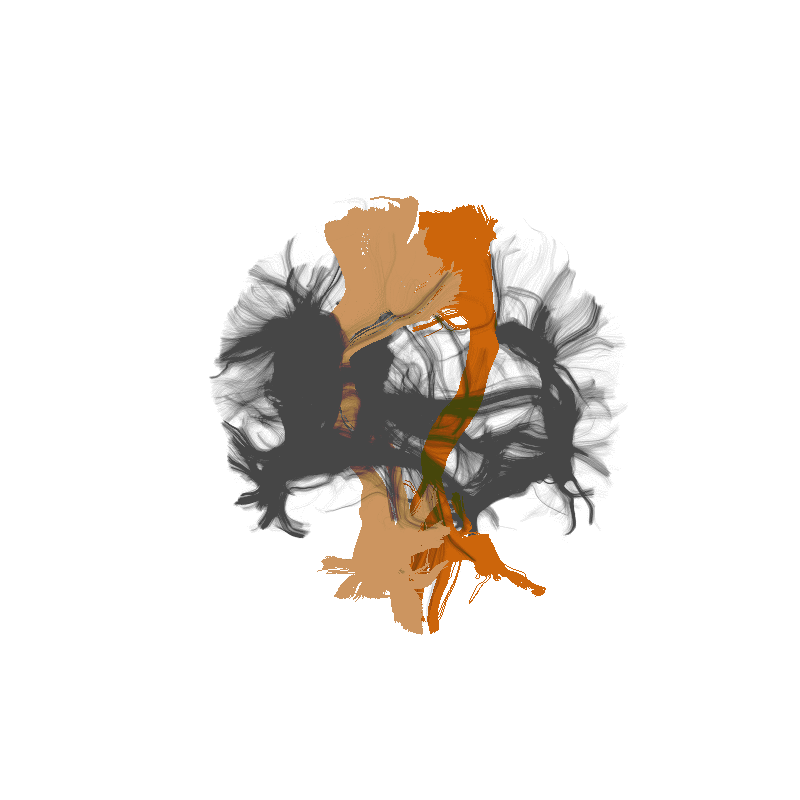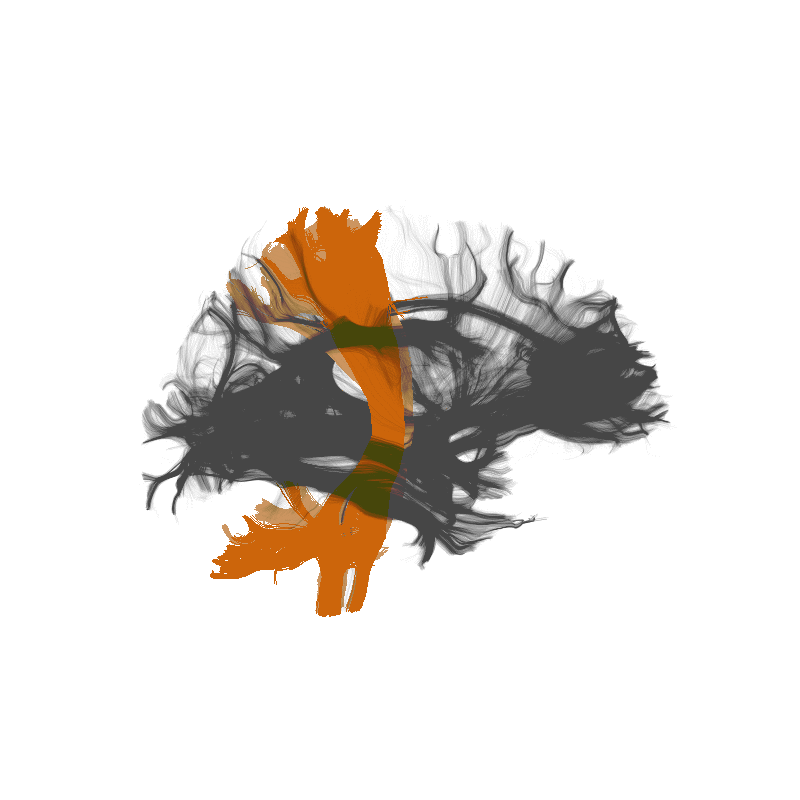
Amyotrophic Lateral Sclerosis (ALS)
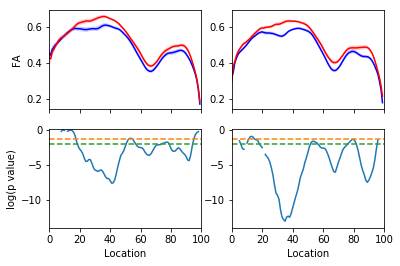
https://yeatmanlab.github.io/Sarica_2017
Automatic data sharing
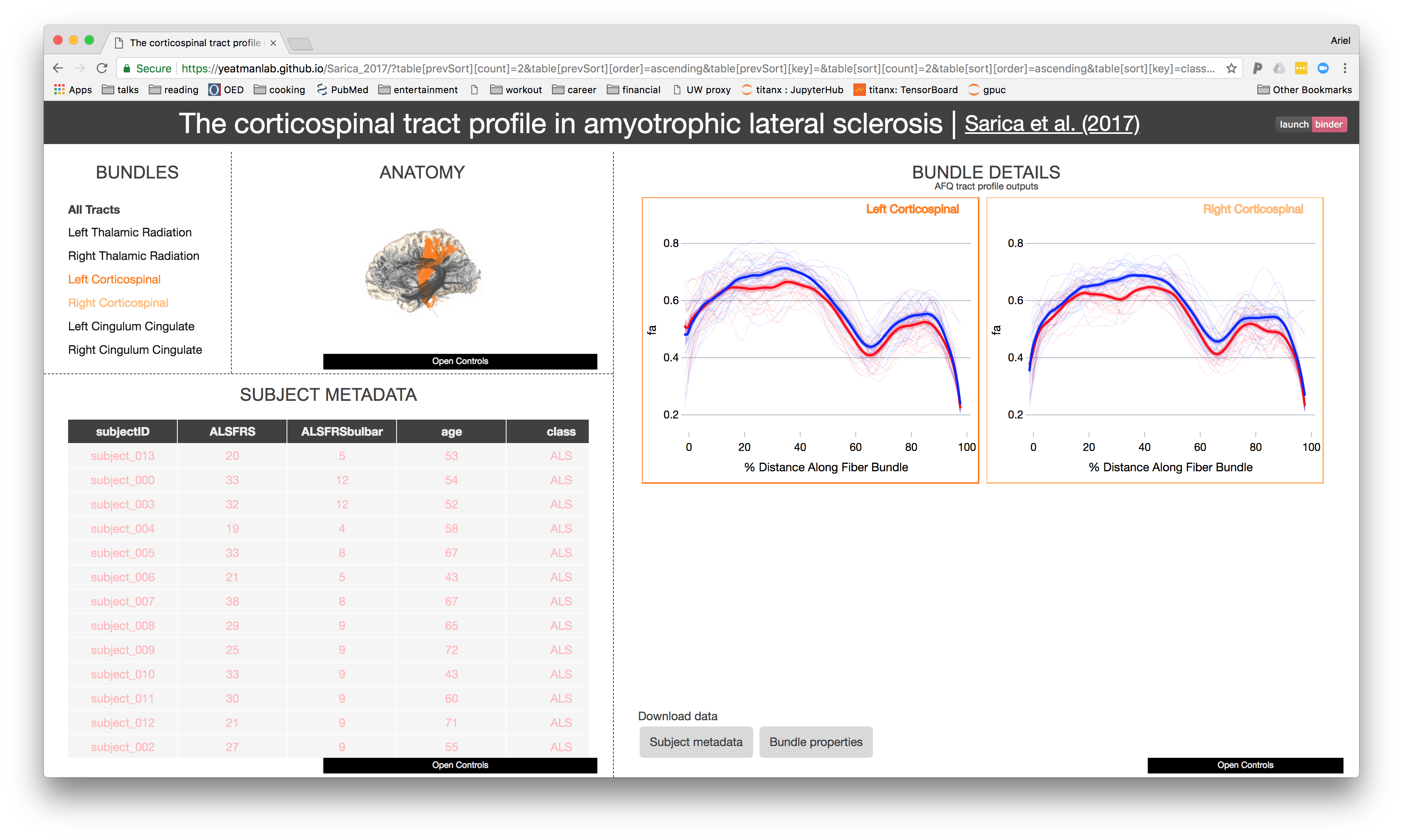
Further exploration
Statistical learning approaches to large datasets
Adam Richie-Halford

Noah Simon
Jason Yeatman
Diffusion MRI data has group structure
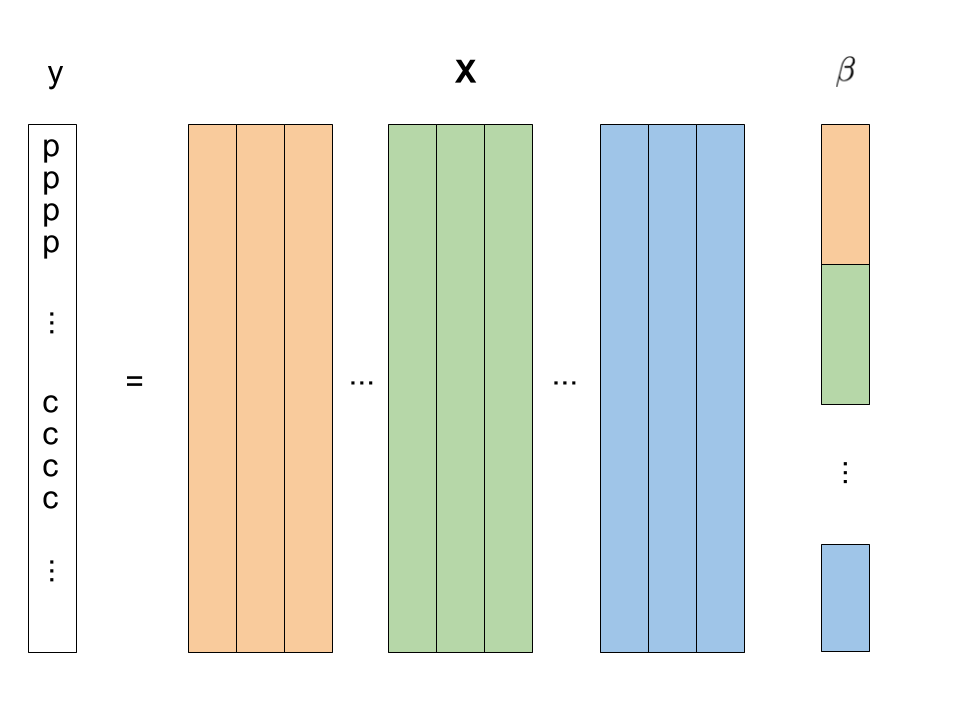
Sparse Group Lasso
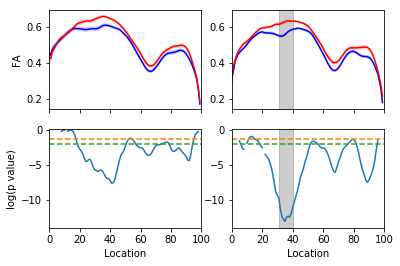
Classification accuracy of ~84% (AUC of 0.9)
Top 10 features selected include CST
Open source software is a necessary complement to brain observatories
Required for reproducibility
Enables building on previous work
https://github.com/akeshavan/braindr-analysis
AFQ-Browser:
https://github.com/yeatmanlab/pyAFQ
https://github.com/yeatmanlab/AFQ-Browser
Sparse Group Lasso:
https://github.com/richford/AFQ-Insight
How do we learn about all of these things?

Similar to the Comp Neuro option
Take a few courses:
Data management
Data analysis
Machine learning and stats
Discussions
Tutorials
Code reviews
...
Neurohackademy
A Summer Institute in Neuroscience and Data Science (=> 2021)

Contact information



