Linear Models
Learning Objectives
- Learners can identify a linear model.
- Learners can use
numpyto fit a linear model to data - Learners can evaluate a model using model residuals.
The main distinction we will make in this lesson is between linear models and non-linear models. Linear models are models that can be described by the following functional form:
\(\mathbf{y} = \beta_0 + \beta_1 \mathbf{x}_1 + \beta_2 \mathbf{x}_2 + ... + \beta_n \mathbf{x}_n + \epsilon\),
where \(\bf{y}\) denotes the dependent variable or variables (that’s why it’s bold-faced: it could be a vector!) in your experiment. \(\bf{x}_i\) are sets of independent variables (also, possibly vectors) and \(\beta_i\) are parameters. Finally, \(\epsilon\) is the noise in the experiment. You can also think about \(\epsilon\) as all the things that your model doesn’t know about. For example, in the visual experiment described, changes in participants wakefulness might affect performance in a systematic way, but unless we explicitely measure wakefulness and add it as an independent variable to our analysis (as another \(\bf{x}\)), we don’t know its value on each trial and it goes into the noise.
All the variables designated as \(\beta_i\) are parameters of the model.
How do we choose \(\beta_i\)?
There are many things you might do to choose the values of the parameters but a common criterion is to select parameters that reduce the sum of the square of the errors (SSE) between the model estimate of the dependent variable and the values of the depenedent variable that was measured in the data. That is if:
\(SSE = \sum{(y - \hat{y})^2}\)
where \(\hat{y}\) is the model estimate of the dependent variable (the “hat” on top of the variable indicates that it is estimated through the model, rather than the one that we measured). Then we will want to find values of the parameters \(\beta_i\) that bring about the smallest possible value of SSE.
As mentioned before, finding good values for the parameters, \(\beta_i\) is called “fitting the model”. It turns out that linear models are easy to fit. Under some fairly generic assumptions (for example that \(\epsilon\) has a zero-mean normal distribution), there is actually an analytic solution to this problem. That is, you can plug it into a formula and get the exact solution: the set of \(\beta_i\) that give you the smallest SSE between the data you collected and the function defined by the parameters.
Fitting a linear model to psychophysics data
Let’s fit a linear model to our data. In our case, a linear model would be a straight line in 2D:
\(y = \beta_0 + \beta_1 x\)
Where, \(\beta_0\) is the intercept and \(\beta_1\) is the slope.
This function is a special case of a larger set of functions called “polynomials” (see below). The numpy library contains a function for fitting these functions, np.polyfit
The function np.polyfit requires three arguments, a vector of x values, a vector of y values and an integer, signifying the degree of the polynomial we wish to fit.
Reading the documentation of polyfit, you will learn that this function returns a tuple with the beta coefficient values, ordered from the highest degree to the lowest degree.
That is, for the linear (degree=1) function we are fitting here, the slope is the first coeffiecient and the intercept of the function is the second coefficient in the tuple. To match the notation we used in our equations, we can assign as:
We can also write the above function as follows, splitting the tuple up as it comes out of the function:
beta1_ortho, beta0_ortho = np.polyfit(x_ortho, y_ortho, 1)
beta1_para, beta0_para = np.polyfit(x_para, y_para, 1)Note that because these values of \(\beta\) are not the “true” values of these coefficients and are just estimates based on the sample we’ve observed, we mark them as an estimate by putting a hat on them: \(\hat{\beta}\).
The inverse of np.polyfit is the function `np.polyval’ that takes these values \(\hat{\beta}\) and values of the independent variable (x), and produces estimated values of the dependent variable: \(\hat{y}\), according to the polynomial function.
We’ll estimate this for a broad range of the independent variable, covering the full range that was in the measurements:
x = np.linspace(0, 1, 100) # What does linspace do?
y_ortho_hat = np.polyval((beta1_ortho, beta0_ortho), x)
y_para_hat = np.polyval((beta1_para, beta0_para), x)Let’s visualize the result of this:
fig, ax = plt.subplots(1)
ax.plot(x, y_ortho_hat)
ax.plot(x_ortho, y_ortho, 'bo')
ax.plot(x, y_para_hat)
ax.plot(x_para, y_para, 'go')
ax.set_xlabel('Contrast 1')
ax.set_ylabel('Proportion responses `1`')
ax.grid('on')
fig.set_size_inches([8,8])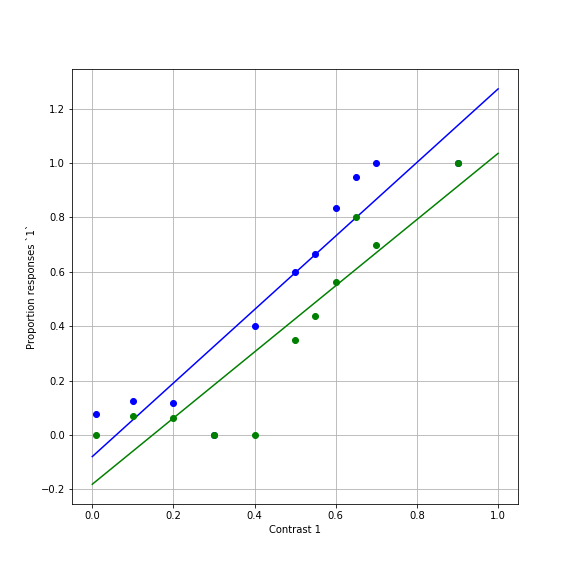
Recall that we wanted to know the value of the PSE for the two conditions. That is the value of x for which \(\hat{y} = 0.5\). For example, for the orthogonal surround condition:
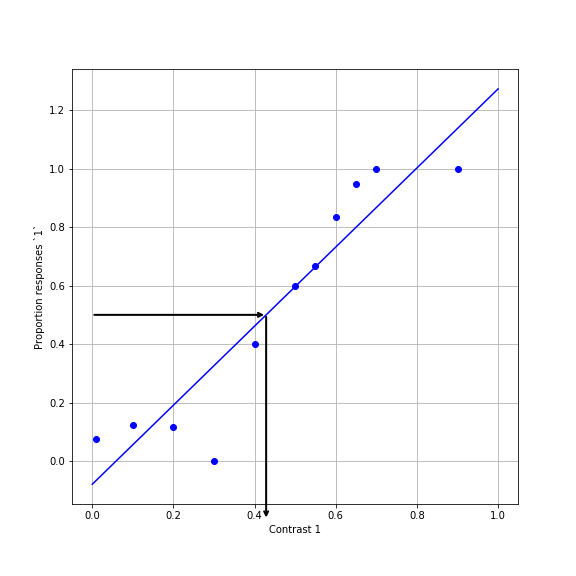
In this case, we’ll need to do a little bit of algebra. We set y=0.5, and solve for x:
\(0.5 = \beta_0 + \beta_1 x\)
\(\Rightarrow 0.5 - \beta_0 = \beta_1 x\)
\(\Rightarrow x = \frac{0.5- \beta_0}{\beta1}\)
Or in code:
Evaluating models
How good is the model? Let’s look at the model “residuals”, the difference between the model and the measured data:
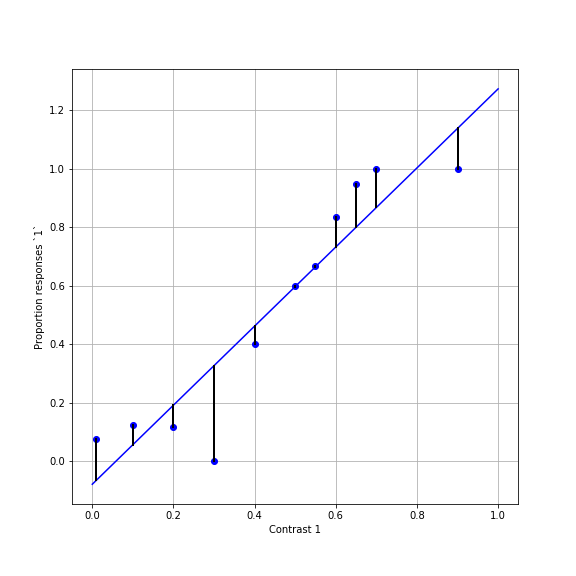
Recall that we wanted to find parameters that would minimize the sum of the squared errors (SSE):
residuals_ortho = x_ortho - np.polyval((beta1_ortho, beta0_ortho), x_ortho)
SSE_ortho = np.sum(residuals_ortho ** 2)
residuals_ortho = x_ortho - np.polyval((beta1_ortho, beta0_ortho), x_ortho)
SSE_ortho = np.sum(residuals_para ** 2)To summarize: This model seems to capture some aspects of the data rather well. For one, it is monotonically increasing. And the SSE doesn’t seem too bad (though that’s hard to assess just by looking at this number). This model tells us that the PSE is at approximately 0.43 for orthogonal condition and approximately 0.56 for the parallel condition. That is, the contrast in the first interval has to be higher than the contrast in the second interval to appear exactly the same. By how much? For the orthogonal condition it’s about 13% and for the parallel condition it’s about 26% (considering that the comparison contrast is always 30%). This makes sense: more suppression for the parallel relative to the orthogonal condition.
But there are also a few problems with this model: It seems to miss a lot of the points. That could be because the data is very noisy, but we can see that the model systematically overshoots the fit for high values of x and systematically undershoots for low values of x. If we had more data, we might see this repeatedly, clueing us in that this is not just a matter of the noise in this data. This might indicate to us that another model might be better for this data.
Finally, another problem is that it seems to produce non-sensical values for some conditions. For example, it sometimes predicts values larger than 1.0 for large contrasts and values smaller than 0.0 for small contrasts. These values are meaningless, because proportion of responses can never be outside the range 0-1. We need to find a different model.
Let’s continue to non-linear models, to see whether we can do better.